Methodology
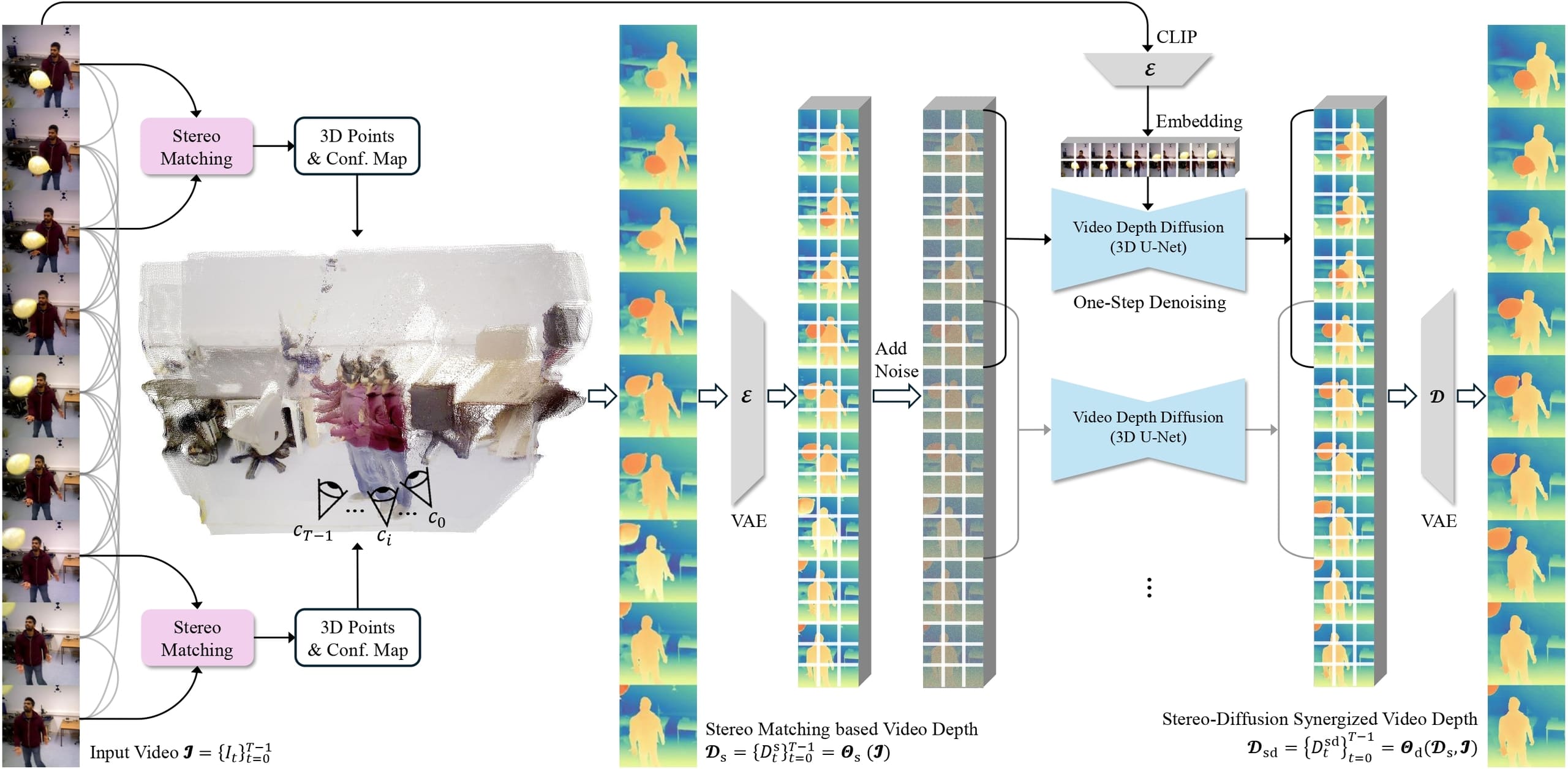
Pipeline of StereoDiff. ① All video frames are paired for stereo matching in the first stage, primarily focusing on static backgrounds, in order to achieve a strong global consistency that provided by global 3D constraints. ② Using the stereo matching-based video depth from the first stage, the second stage of StereoDiff applies a single-step video depth diffusion for significantly improving the local consistency without sacrificing its original global consistency, resulting in video depth estimations with both strong global consistency and smooth local consistency.
Experiments
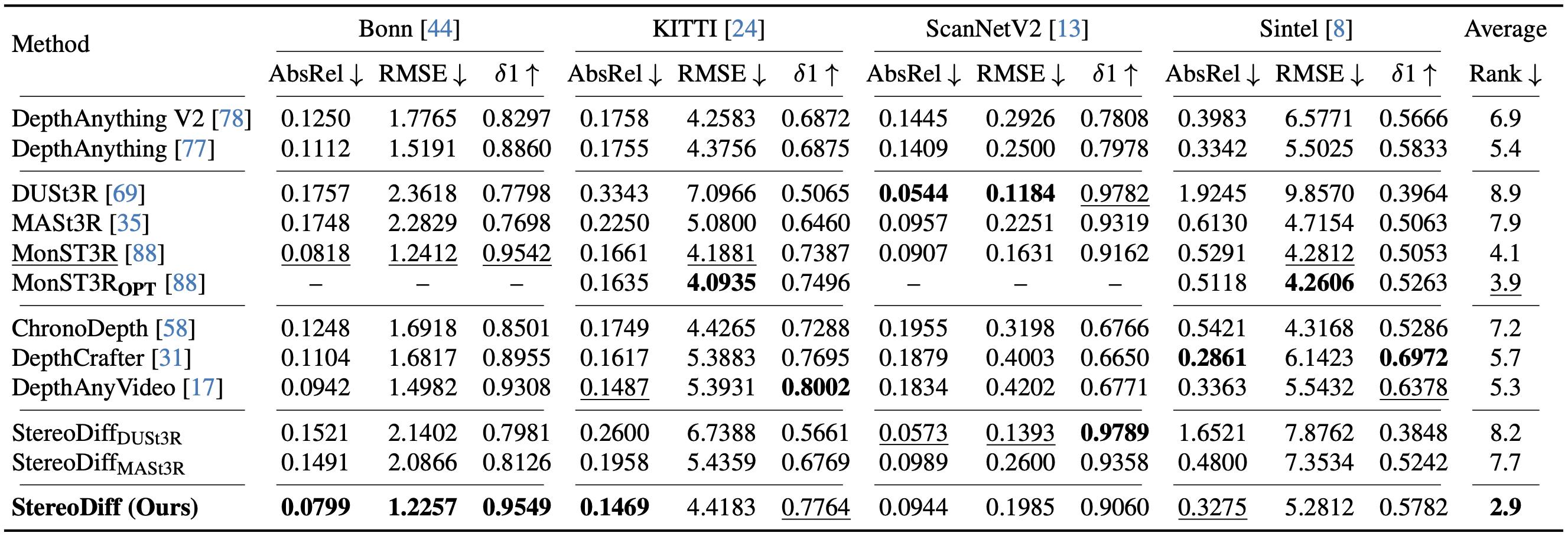
Quantitative comparison of StereoDiff with SoTA methods on zero-shot video depth benchmarks. The five sections from top to bottom represent: image depth estimators, stereo matching-based estimators, video depth diffusion models, StereoDiff using other stereo matching methods, and StereoDiff. To make sure a comprehensive evaluation, we used four datasets: Bonn, KITTI, ScanNetV2, and Sintel. We report the mean metrics of StereoDiff across 10 independent runs. MonST3ROPT (OPT: with optimization) can not be evaluated on long video depth benchmarks (i.e., Bonn and ScanNetV2) due to computational constraints. Best results are bolded and the second best are underlined.
No temporal consistency metrics?
The metrics above are not in per-frame manner. All frames in a predicted video depth use same scale and shift factors for affine-invariant evaluation. Temporal inconsistencies will lead to worse metrics. Testing MonST3R on Bonn with per-frame scale and shift yields an AbsRel of 0.0341, much better than the reported 0.0818.